 El equipo de Fedora ha lanzado su última versión de la distribución Linux de escritorio y esta vez hay incluso más versiones disponibles para probar.
El equipo de Fedora ha lanzado su última versión de la distribución Linux de escritorio y esta vez hay incluso más versiones disponibles para probar.
- Visto: 44

El equipo de Fedora ha lanzado su última versión de la distribución Linux de escritorio y esta vez hay incluso más versiones disponibles para probar.
 OpenProject es una poderosa herramienta de gestión de proyectos de código abierto que permite planificar, colaborar y seguir el progreso de los proyectos de manera eficiente. A continuación te mostraré detalladamente cómo configurar OpenProject empleando Docker en un entorno Linux.
OpenProject es una poderosa herramienta de gestión de proyectos de código abierto que permite planificar, colaborar y seguir el progreso de los proyectos de manera eficiente. A continuación te mostraré detalladamente cómo configurar OpenProject empleando Docker en un entorno Linux.
 Ya está disponible la quinta versión candidata semanal de Linux 6.9, mientras el ciclo del núcleo parece estar a punto de concluir a mediados de mayo.
Ya está disponible la quinta versión candidata semanal de Linux 6.9, mientras el ciclo del núcleo parece estar a punto de concluir a mediados de mayo.
 Implementar un software ERP (Enterprise Resource Planning "Planificación de Recursos Empresariales" en español) en una óptica resulta muy beneficioso para optimizar la gestión del negocio y mejorar la atención al cliente.
Implementar un software ERP (Enterprise Resource Planning "Planificación de Recursos Empresariales" en español) en una óptica resulta muy beneficioso para optimizar la gestión del negocio y mejorar la atención al cliente.
 Supervisar el rendimiento en sistemas Linux es fundamental para asegurar un desempeño óptimo y detectar posibles inconvenientes antes de que impacten en la experiencia del usuario o la eficiencia. Automatizar esta labor no solo ahorra tiempo y recursos, sino que también posibilita una vigilancia constante y preventiva. En esta publicación, abordaremos la automatización de la supervisión del rendimiento en Linux para potenciar la eficacia del sistema.
Supervisar el rendimiento en sistemas Linux es fundamental para asegurar un desempeño óptimo y detectar posibles inconvenientes antes de que impacten en la experiencia del usuario o la eficiencia. Automatizar esta labor no solo ahorra tiempo y recursos, sino que también posibilita una vigilancia constante y preventiva. En esta publicación, abordaremos la automatización de la supervisión del rendimiento en Linux para potenciar la eficacia del sistema.
 Ubuntu Studio sigue siendo la forma más rápida de acceder a Linux y al software libre para música, sonido, vídeo, multimedia y 3D. Y merecen un poco de amor extra ahora, especialmente desde que Apple Silicon ha desinflado ligeramente la atención de Linux de escritorio. He aquí un vistazo a la versión de soporte a largo plazo que acaba de llegar a beta, prevista para finales de este mes.
Ubuntu Studio sigue siendo la forma más rápida de acceder a Linux y al software libre para música, sonido, vídeo, multimedia y 3D. Y merecen un poco de amor extra ahora, especialmente desde que Apple Silicon ha desinflado ligeramente la atención de Linux de escritorio. He aquí un vistazo a la versión de soporte a largo plazo que acaba de llegar a beta, prevista para finales de este mes.
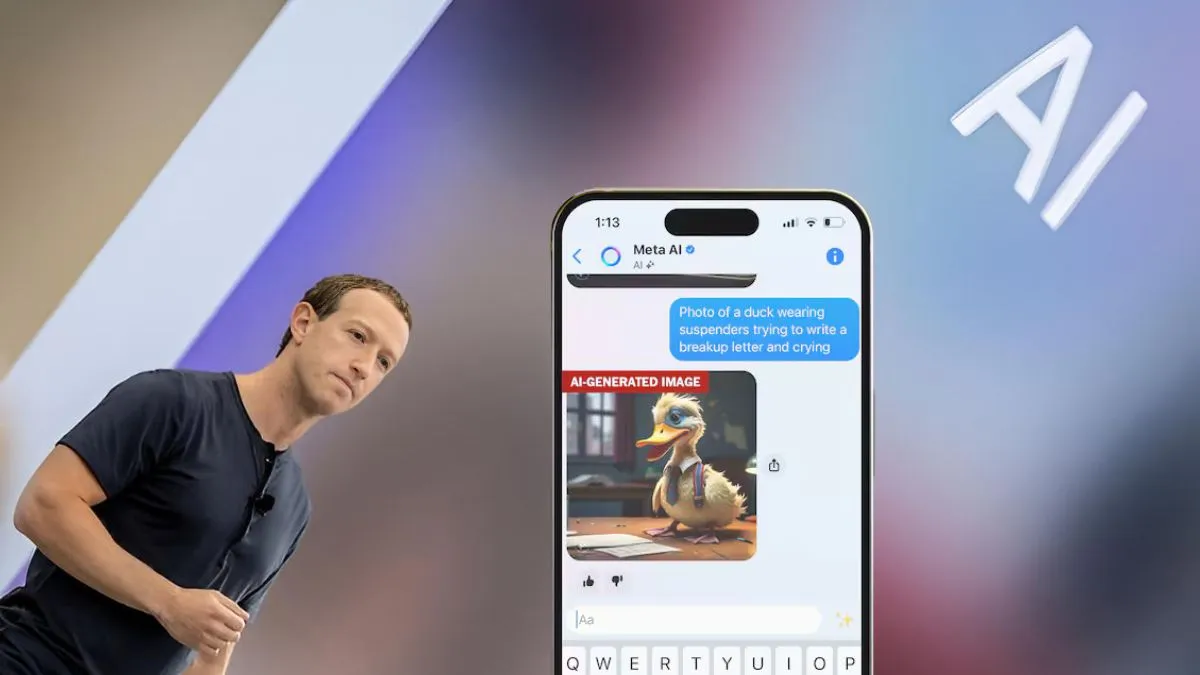 Con aparentemente menos amigos publicando en sus feeds principales de Facebook e Instagram, Meta ha introducido una nueva función con la que sus usuarios pueden hablar: un chatbot de IA, Facebook, Instagram, Messenger y WhatsApp impulsan un nuevo chatbot con inteligencia artificial.
Con aparentemente menos amigos publicando en sus feeds principales de Facebook e Instagram, Meta ha introducido una nueva función con la que sus usuarios pueden hablar: un chatbot de IA, Facebook, Instagram, Messenger y WhatsApp impulsan un nuevo chatbot con inteligencia artificial.
 El recién lanzado modelo de inteligencia artificial de Google, Lumiere, emplea un innovador enfoque de procesamiento de vídeo conocido como Space-Time-U-Net (STUNet). Este método calcula la posición de los elementos en un vídeo (espacio) y su movimiento y cambio simultáneos (tiempo). Según informa Ars Technica, Lumiere puede generar el vídeo de manera integral en un solo proceso, evitando la necesidad de unir fragmentos de fotogramas más pequeños.
El recién lanzado modelo de inteligencia artificial de Google, Lumiere, emplea un innovador enfoque de procesamiento de vídeo conocido como Space-Time-U-Net (STUNet). Este método calcula la posición de los elementos en un vídeo (espacio) y su movimiento y cambio simultáneos (tiempo). Según informa Ars Technica, Lumiere puede generar el vídeo de manera integral en un solo proceso, evitando la necesidad de unir fragmentos de fotogramas más pequeños.
 En un mundo cada vez más digitalizado, la privacidad y la seguridad de nuestros datos son temas de suma importancia. Las distribuciones de Linux han ganado popularidad por su enfoque en la privacidad y la seguridad, ofreciendo a los usuarios opciones robustas y confiables para proteger su información. Si bien es cierto Kali Linux siempre esta en el top, estas distribuciones son una opción sobre todo para privacidad y seguridad en el año 2024.
En un mundo cada vez más digitalizado, la privacidad y la seguridad de nuestros datos son temas de suma importancia. Las distribuciones de Linux han ganado popularidad por su enfoque en la privacidad y la seguridad, ofreciendo a los usuarios opciones robustas y confiables para proteger su información. Si bien es cierto Kali Linux siempre esta en el top, estas distribuciones son una opción sobre todo para privacidad y seguridad en el año 2024.
 El Día del Hardware Libre es una ocasión especial que resalta la importancia del hardware de código abierto y su relación con el software libre. Esta celebración, que tiene lugar el tercer sábado de abril de cada año, es un recordatorio de cómo el hardware libre fortalece y complementa al software libre en el ecosistema tecnológico.
El Día del Hardware Libre es una ocasión especial que resalta la importancia del hardware de código abierto y su relación con el software libre. Esta celebración, que tiene lugar el tercer sábado de abril de cada año, es un recordatorio de cómo el hardware libre fortalece y complementa al software libre en el ecosistema tecnológico.
 A medida que la tecnología avanza, los sistemas operativos buscan mejorar sus funcionalidades para ofrecer una experiencia de usuario más completa y eficiente. A continuación las 10 funciones específicas de Linux que sería genial ver implementadas en macOS para mejorar la productividad y la experiencia del usuario.
A medida que la tecnología avanza, los sistemas operativos buscan mejorar sus funcionalidades para ofrecer una experiencia de usuario más completa y eficiente. A continuación las 10 funciones específicas de Linux que sería genial ver implementadas en macOS para mejorar la productividad y la experiencia del usuario.
 Mientras que Fedora 41, a finales de 2024, aspira a tener más compilaciones de paquetes reproducibles, openSUSE Factory ya ha logrado un hito importante en las compilaciones reproducibles bit a bit.
Mientras que Fedora 41, a finales de 2024, aspira a tener más compilaciones de paquetes reproducibles, openSUSE Factory ya ha logrado un hito importante en las compilaciones reproducibles bit a bit.
 La gestión de datos espaciales es fundamental en numerosas disciplinas, desde la planificación urbana hasta la gestión medioambiental y la agricultura de precisión. En este artículo, exploraremos algunas de las principales herramientas de software libre para la gestión de datos espaciales, ofreciendo alternativas sólidas a ArcGIS.
La gestión de datos espaciales es fundamental en numerosas disciplinas, desde la planificación urbana hasta la gestión medioambiental y la agricultura de precisión. En este artículo, exploraremos algunas de las principales herramientas de software libre para la gestión de datos espaciales, ofreciendo alternativas sólidas a ArcGIS.
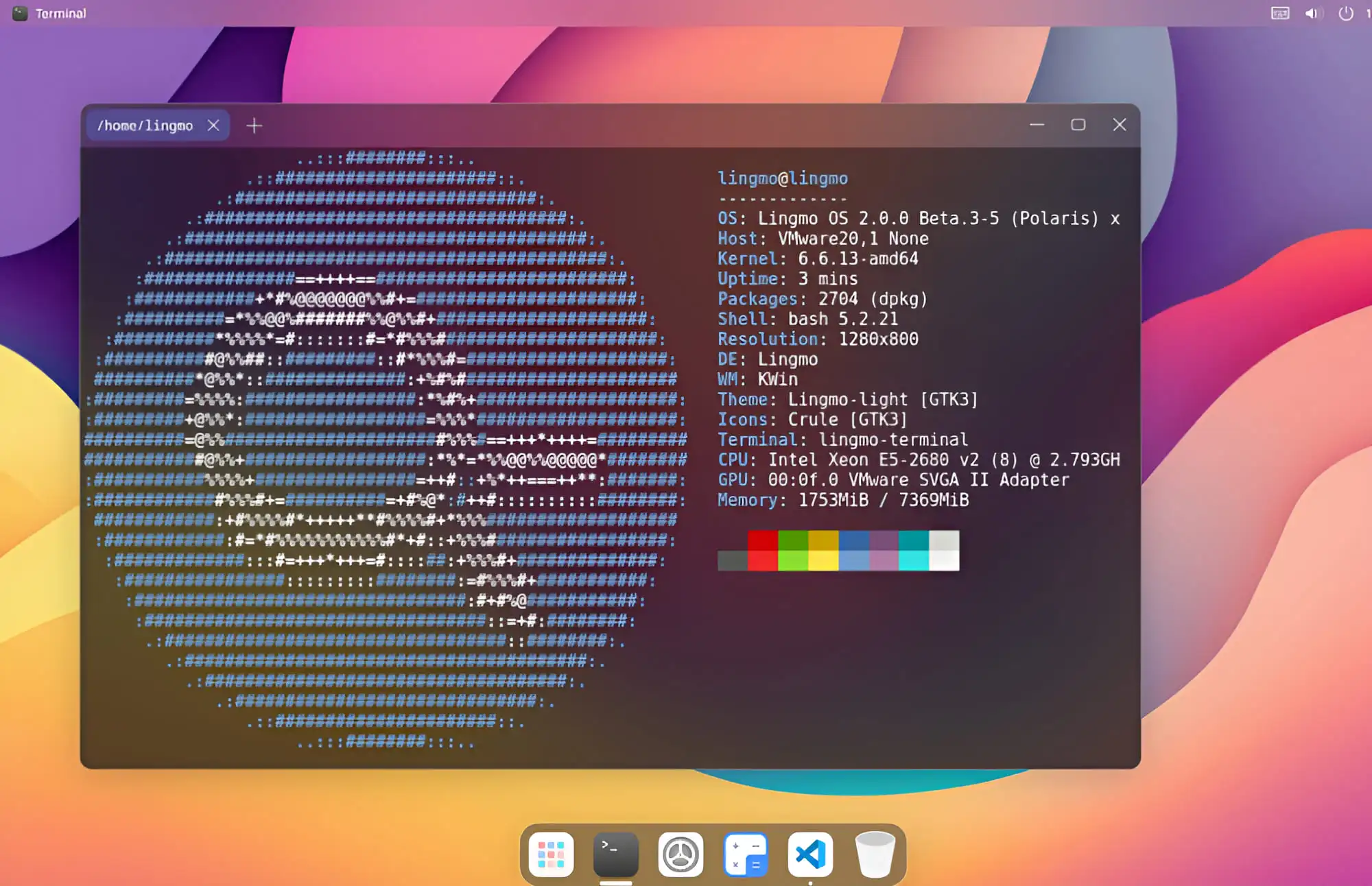 Lo bueno de Linux es que cualquiera puede lanzarse a desarrollar un sistema operativo completo tomando componentes de otros proyectos de código abierto o creándolos desde cero.
Lo bueno de Linux es que cualquiera puede lanzarse a desarrollar un sistema operativo completo tomando componentes de otros proyectos de código abierto o creándolos desde cero.
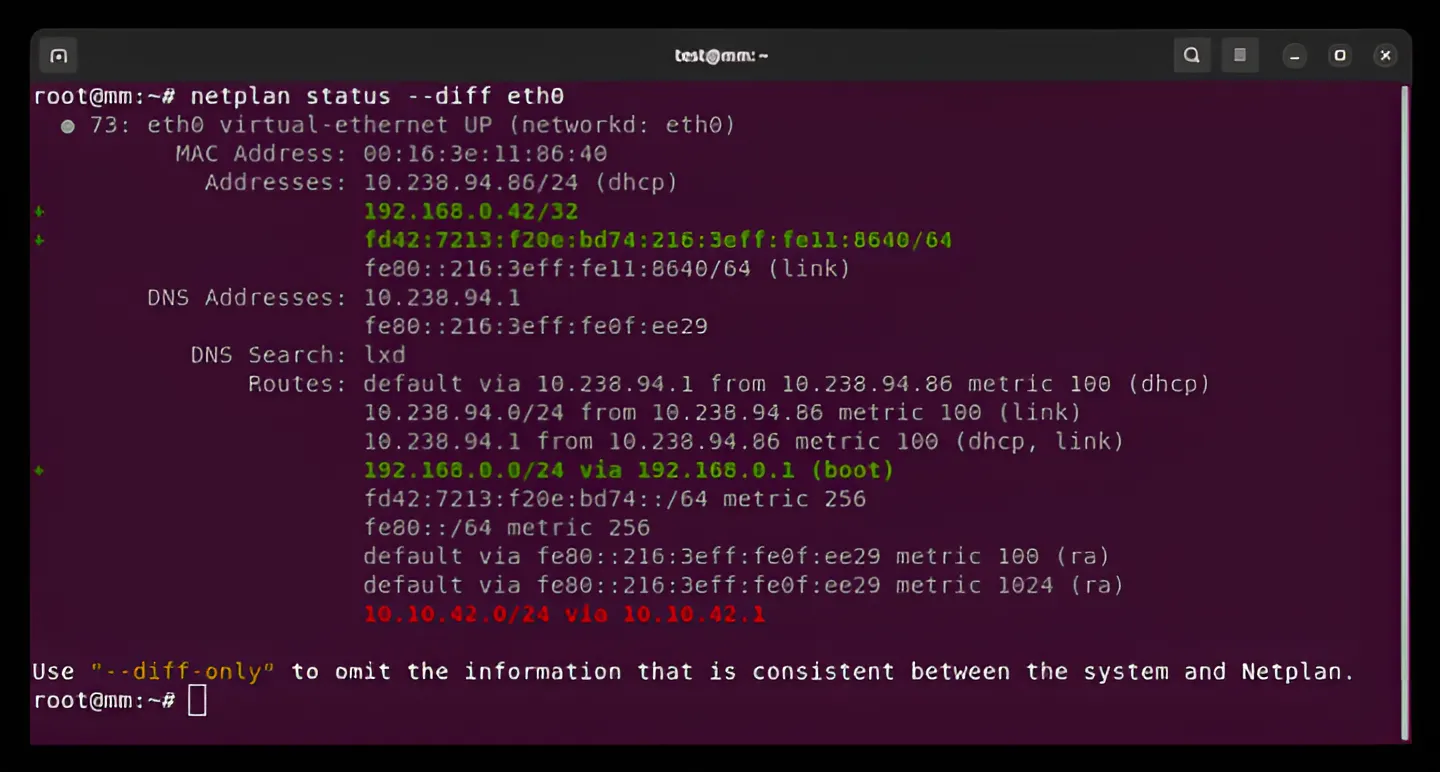 Canonical ha anunciado la liberación general de Netplan 1.0, la primera versión estable de su renderizador de abstracción de configuración de red, tras siete años de desarrollo. Aunque la versión 1.0 es más un hito simbólico que un avance tecnológico significativo, dado que el software ha estado en uso durante algún tiempo y viene preinstalado en Ubuntu, aún así presenta aspectos interesantes.
Canonical ha anunciado la liberación general de Netplan 1.0, la primera versión estable de su renderizador de abstracción de configuración de red, tras siete años de desarrollo. Aunque la versión 1.0 es más un hito simbólico que un avance tecnológico significativo, dado que el software ha estado en uso durante algún tiempo y viene preinstalado en Ubuntu, aún así presenta aspectos interesantes.
 Las contribuciones de código generadas y asistidas por IA ya no están permitidas en la distribución Gentoo Linux.
Las contribuciones de código generadas y asistidas por IA ya no están permitidas en la distribución Gentoo Linux.
 Esta versión también añade la posibilidad de evitar que el módulo del kernel de VirtualBox se cargue automáticamente durante el arranque del sistema.
Esta versión también añade la posibilidad de evitar que el módulo del kernel de VirtualBox se cargue automáticamente durante el arranque del sistema.
 El análisis de datos se ha convertido en un pilar fundamental en diversas áreas, desde la toma de decisiones empresariales hasta la investigación científica. En el ecosistema de Linux, existen numerosas herramientas libres que permiten realizar análisis de datos de manera efectiva y potente.
El análisis de datos se ha convertido en un pilar fundamental en diversas áreas, desde la toma de decisiones empresariales hasta la investigación científica. En el ecosistema de Linux, existen numerosas herramientas libres que permiten realizar análisis de datos de manera efectiva y potente.
 TensorFlow es una de las herramientas más potentes y populares para el desarrollo de aplicaciones de inteligencia artificial, incluyendo tareas de procesamiento de lenguaje natural como la generación de texto predictivo. En este artículo, te guiaré paso a paso en el proceso de desarrollar tu primera aplicación utilizando TensorFlow para generar texto predictivo.
TensorFlow es una de las herramientas más potentes y populares para el desarrollo de aplicaciones de inteligencia artificial, incluyendo tareas de procesamiento de lenguaje natural como la generación de texto predictivo. En este artículo, te guiaré paso a paso en el proceso de desarrollar tu primera aplicación utilizando TensorFlow para generar texto predictivo.
 Utilice el marco INSPIRe para ahorrar tiempo y obtener una ventaja competitiva (ChatGPT-4 - Claude 3 - Gemini)
Utilice el marco INSPIRe para ahorrar tiempo y obtener una ventaja competitiva (ChatGPT-4 - Claude 3 - Gemini)
 Los Entornos de Desarrollo Integrados (IDEs, por sus siglas en inglés) son herramientas esenciales para los programadores de Python, ya que ofrecen una amplia gama de funcionalidades que facilitan la escritura, depuración y gestión de proyectos.
Los Entornos de Desarrollo Integrados (IDEs, por sus siglas en inglés) son herramientas esenciales para los programadores de Python, ya que ofrecen una amplia gama de funcionalidades que facilitan la escritura, depuración y gestión de proyectos.
 Esta versión también actualiza el manejo del microcódigo, establece la distribución del teclado para la instalación mínima y añade udev sync antes de lsblk que sigue al formateo.
Esta versión también actualiza el manejo del microcódigo, establece la distribución del teclado para la instalación mínima y añade udev sync antes de lsblk que sigue al formateo.
 Linus Torvalds, el jefe supremo del núcleo Linux, ha hecho más ambiguo el uso de la sangría en los archivos de configuración del núcleo, intencionadamente para eliminar a los analizadores inferiores.
Linus Torvalds, el jefe supremo del núcleo Linux, ha hecho más ambiguo el uso de la sangría en los archivos de configuración del núcleo, intencionadamente para eliminar a los analizadores inferiores.
 La instalación y configuración de servicios web como Apache y NGINX es fundamental para alojar y gestionar sitios web en entornos Linux. Estos servidores web son ampliamente utilizados debido a su estabilidad, rendimiento y flexibilidad.
La instalación y configuración de servicios web como Apache y NGINX es fundamental para alojar y gestionar sitios web en entornos Linux. Estos servidores web son ampliamente utilizados debido a su estabilidad, rendimiento y flexibilidad.
 Los juegos de azar llevan con nosotros toda la vida. Éstos surgieron hace siglos como una forma de entretenimiento, e incluso en épocas pasadas las personas ya comenzaban a jugarse ciertos objetos para dotar de más emoción a este tipo de juegos.
Los juegos de azar llevan con nosotros toda la vida. Éstos surgieron hace siglos como una forma de entretenimiento, e incluso en épocas pasadas las personas ya comenzaban a jugarse ciertos objetos para dotar de más emoción a este tipo de juegos.
Para más información sobre casinos online confiables en Perú, puedes visitar sitio web https://CasinoHex.pe/
Encuentra los casinos online confiables en CasinoHEX Chile
BeTragaperras " Juega gratis las mejores tragamonedas online españolas"
Niñeras, Empleadas Domésticas, Cuidadoras Infantiles, personal seleccionado en Lima Perú